Собеседование по Java EE — SQL, JDBC (вопросы и ответы)
Вопросы и ответы для собеседования о применении SQL, JDBC в Java разработке.
к списку вопросов раздела JEE
Собеседование по Java EE — SQL, JDBC (вопросы и ответы). Часть 2.
Вопросы
1. ANSI SQL
2. Основные элементы баз данных – таблицы, процедуры, функции, констрейнты и т.д..
3. Как вы понимаете null в базах данных?
4. Агрегатные функции, как они работают с null. Не забудьте о group by и having
5. Каким образом лучше добавлять большое количество записей в таблицу?
6. Что такое первая нормальная форма и процесс нормализации? Какие бывают нормальные формы?
7. В чем смысл индекса СУБД, как они устроены, как хранятся? Как бы вы реализовали тот же функционал?
8. Что такое JDBC API и когда его используют?
9. Что такое JDBC Driver и какие различные типы драйверов JDBC вы знаете?
10. Как JDBC API помогает достичь слабой связи между Java программой и JDBC Drivers API?
11. Что такое JDBC Connection? Покажите шаги для подключения программы к базе данных.
12. Как используется JDBC DriverManager class?
13. Как получить информацию о сервере базы данных из java программы?
14. Что такое JDBC Statement?
15. Какие различия между execute, executeQuery, executeUpdate?
16. Что такое JDBC PreparedStatement?
17. Как установить NULL значения в JDBC PreparedStatement?
18. Как используется метод getGeneratedKeys() в Statement?
19. Какие преимущества в использовании PreparedStatement над Statement?
20. Какие есть ограничения PreparedStatement и как их преодолеть?
21. Что такое JDBC ResultSet?
22. Какие существуют различные типы JDBC ResultSet?
23. Как используются методы setFetchSize() и SetMaxRows() в Statement?
24. Как вызвать Stored Procedures используя JDBC API?
25. Что такое JDBC Batch Processing и какие его преимущества?
26. Что такое JDBC Transaction Management и зачем он нужен?
27. Как откатить JDBC транзакцию?
28. Что такое JDBC Savepoint и как он используется?
29. Расскажите о JDBC DataSource. Какие преимущества он дает?
30. Как создать JDBC пул соединений используя JDBC DataSource и JNDI в Apache Tomcat Server?
31. Расскажите про Apache DBCP API.
32. Какие вы знаете уровни изоляции соединений в JDBC?
33. Что вы знаете о JDBC RowSet? Какие существуют различные типы RowSet?
34. В чем разница между ResultSet и RowSet?
35. Приведите пример наиболее распространенных исключений в JDBC.
36. Расскажите о типах данных CLOB и BLOB в JDBC.
37. Что вы знаете о «грязном чтении» (dirty read) в JDBC? Какой уровень изоляции предотвращает этот тип чтения?
38. Какие есть две фазы commit?
39. Приведите пример различных типов блокировки в JDBC.
40. Как вы понимаете DDL и DML выражения?
41. Какая разница между java.util.Date и java.sql.Date?
42. Как вставить изображение или необработанные данные в базу данных?
43. Что вы можете рассказать о фантомном чтении? Какой уровень изоляции его предотвращает?
44. Что такое SQL Warning? Как возвратить SQL предупреждения в JDBC программе?
45. Как запустить Oracle Stored Procedure с объектами базы данных IN/OUT?
46. Приведите пример возникновения java.sql.SQLException: No suitable driver found.
47. Best Practices в JDBC.
Ответы
1. ANSI SQL
SQL (structured query language — «язык структурированных запросов») — формальный непроцедурный язык программирования, применяемый для создания, модификации и управления данными в произвольной реляционной базе данных, управляемой соответствующей системой управления базами данных (СУБД). SQL основывается на исчислении кортежей. Стандарт SQL определяется с помощью кода ANSI.
*Вопрос «расскажите о SQL» очень широкий и не вписывается в рамки этой статьи. К прочтению любая информация из интернета, например:
SQL : ОБЗОР: http://www.sql.ru/docs/sql/u_sql/ch2.shtml
Wiki: https://ru.wikipedia.org/wiki/SQL
2. Основные элементы баз данных – таблицы, процедуры, функции, констрейнты и т.д.
Поле — это минимальный элемент базы данных, содержащий один неделимый квант информации. Каждое поле характеризуется именем и типом хранящихся в нем данных.
Запись — это совокупность нескольких разнородных полей, описывающая некоторую сущность предметной области.
Таблица базы данных — это набор однородных записей.
Хранимая процедура — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам. В хранимых процедурах могут выполняться стандартные операции с базами данных (как DDL, так и DML). Кроме того, в хранимых процедурах возможны циклы и ветвления, то есть в них могут использоваться инструкции управления процессом исполнения.
|
1 2 3 4 5 6 7 8 |
CREATE [OR REPLACE] PROCEDURE имя_процедуры [ (параметр [, параметр, …]) ] IS [локальные объявления] BEGIN исполняемые предложения [EXCEPTION обработчики исключений] END [имя_процедуры]; |
Функция – это подпрограмма, которая вычисляет значение. Существует большое количество встроенных функций (могут разниться для разных БД).
|
1 2 3 4 5 6 7 8 9 |
CREATE [OR REPLACE] FUNCTION имя_функции [ (параметр [, параметр, …]) ] RETURN тип_данных IS | AS [локальные объявления] BEGIN исполняемые предложения [EXCEPTION обработчики исключений] END [имя_функции]; |
Констрейнты (constraints) — объявление правил (ограничения), которым должны соответствовать данные в таблице.
|
1 2 3 4 5 6 7 8 9 |
CREATE TABLE table_name ( column_name1 data_type(size) constraint_name, column_name2 data_type(size) constraint_name, column_name3 data_type(size) constraint_name, .... ); Например для задания первичного ключа, можно использовать такую запись: CONSTRAINT <имя ограничения> PRIMARY KEY (<список столбцов, являющихся первичным ключом>) |
Типы констрейнтов:
- NOT NULL -колонка не может содержать NULL значений.
- UNIQUE — каждая строка в колонке должна иметь уникальное значение.
- PRIMARY KEY — комбинация NOT NULL и UNIQUE.
- FOREIGN KEY — обеспечивает ссылочную целостность. Означает что ссылающиеся данные имеют соответствие в другой таблице.
- CHECK — проверка на определенное выполнение правил.
- DEFAULT — задает значение по умолчанию для колонки
3. Как вы понимаете null в базах данных?
Смысл NULL-значения — это отсутствие информации или неприменимость данного атрибута в данном кортеже.
NULL-значение может означать неприменимость значения к этому столбцу (например в колонке «скорость полета» для таблицы животные и записи «Слон»)
NULL-значение так же может означать отсутствие информации. Заменять отсутствующие значения, например на -1, ‘ ‘ или что-то такое, не корректно.
О NULL-значениях: http://www.sql-tutorial.ru/ru/book_once_more_about_null_values.html
4. Агрегатные функции, как они работают с null. Не забудьте о group by и having
Стандартом предусмотрены следующие агрегатные функции:
| название | описание |
|---|---|
| COUNT(*) | Возвращает количество строк источника записей |
| COUNT | Возвращает количество значений в указанном столбце |
| SUM | Возвращает сумму значений в указанном столбце |
| AVG | Возвращает среднее значение в указанном столбце |
| MIN | Возвращает минимальное значение в указанном столбце |
| MAX | Возвращает максимальное значение в указанном столбце |
Все эти функции возвращают единственное значение. При этом функции COUNT, MIN и MAX применимы к данным любого типа, в то время как SUM и AVG используются только для данных числового типа. Разница между функцией COUNT(*) и COUNT(имя столбца | выражение) состоит в том, что вторая (как и остальные агрегатные функции) при подсчете не учитывает NULL-значения.
Предложение GROUP BY используется для определения групп выходных строк, к которым могут применяться агрегатные функции (COUNT, MIN, MAX, AVG и SUM).
Если предложение WHERE определяет предикат для фильтрации строк, то предложение HAVING применяется после группировки для определения аналогичного предиката, фильтрующего группы по значениям агрегатных функций. Это предложение необходимо для проверки значений, которые получены с помощью агрегатной функции не из отдельных строк источника записей, определенного в предложении FROM, а из групп таких строк. Поэтому такая проверка не может содержаться в предложении WHERE.
Получение итоговых значений: http://www.sql-tutorial.ru/ru/book_getting_summarizing_values.html
Предложение GROUP BY: http://www.sql-tutorial.ru/ru/book_group_by_clause.html
Предложение HAVING: http://www.sql-tutorial.ru/ru/book_having_clause.html
5. Каким образом лучше добавлять большое количество записей в таблицу?
Можно трактовать такой вопрос по разному. Один из ответов — использовать подзапрос:
|
1 2 3 4 |
INSERT INTO <имя таблицы>[(<имя столбца>,...)] SELECT * FROM <имя таблицы> WHERE value = 'something'; |
6. Что такое первая нормальная форма и процесс нормализации? Какие бывают нормальные формы?
Первая нормальная форма (1NF) — базовая нормальная форма отношения в реляционной модели данных.
Нормальная форма — свойство отношения в реляционной модели данных, характеризующее его с точки зрения избыточности, потенциально приводящей к логически ошибочным результатам выборки или изменения данных. Нормальная форма определяется как совокупность требований, которым должно удовлетворять отношение. Нормальные формы: первая нормальная форма, вторая нормальная форма, третья нормальная форма, нормальная форма Бойса — Кодда, четвёртая нормальная форма, пятая нормальная форма.
Тема является базовой и необходима к детальному изучению. Размер ответа на этот вопрос не соответствует формату данной статьи.
7. В чем смысл индекса СУБД, как они устроены, как хранятся? Как бы вы реализовали тот же функционал?
Индекс (англ. index) — объект базы данных, создаваемый с целью повышения производительности поиска данных. Таблицы в базе данных могут иметь большое количество строк, которые хранятся в произвольном порядке, и их поиск по заданному критерию путем последовательного просмотра таблицы строка за строкой может занимать много времени. Индекс формируется из значений одного или нескольких столбцов таблицы и указателей на соответствующие строки таблицы и, таким образом, позволяет искать строки, удовлетворяющие критерию поиска. Ускорение работы с использованием индексов достигается в первую очередь за счёт того, что индекс имеет структуру, оптимизированную под поиск — например, сбалансированного дерева.
Ответ на этот вопрос так же не поместится в одну статью. Изучите самостоятельно.
Обзор типов индексов Oracle, MySQL, PostgreSQL, MS SQL: http://habrahabr.ru/post/102785/
8. Что такое JDBC API и когда его используют?
JDBC – это стандарт взаимодействия приложения с различными СУБД. JDBC основан на концепции драйверов, позволяющей получать соединение с БД по специальному url. JDBC API находятся в пакетах java.sql и javax.sql. С помощью JDBC API можно создавать соединения с БД, выполнять SQL запросы, хранимые процедуры и обрабатывать результаты. JDBC API упрощает работу с базами данных из Java программ.
Урок JDBC в примерах: http://habrahabr.ru/sandbox/41444/
9. Что такое JDBC Driver и какие различные типы драйверов JDBC вы знаете?
JDBC основан на концепции так называемых драйверов, позволяющих получать соединение с базой данных по специально описанному URL. Драйверы могут загружаться динамически (во время работы программы). Загрузившись, драйвер сам регистрирует себя и вызывается автоматически, когда программа требует URL, содержащий протокол, за который драйвер отвечает.
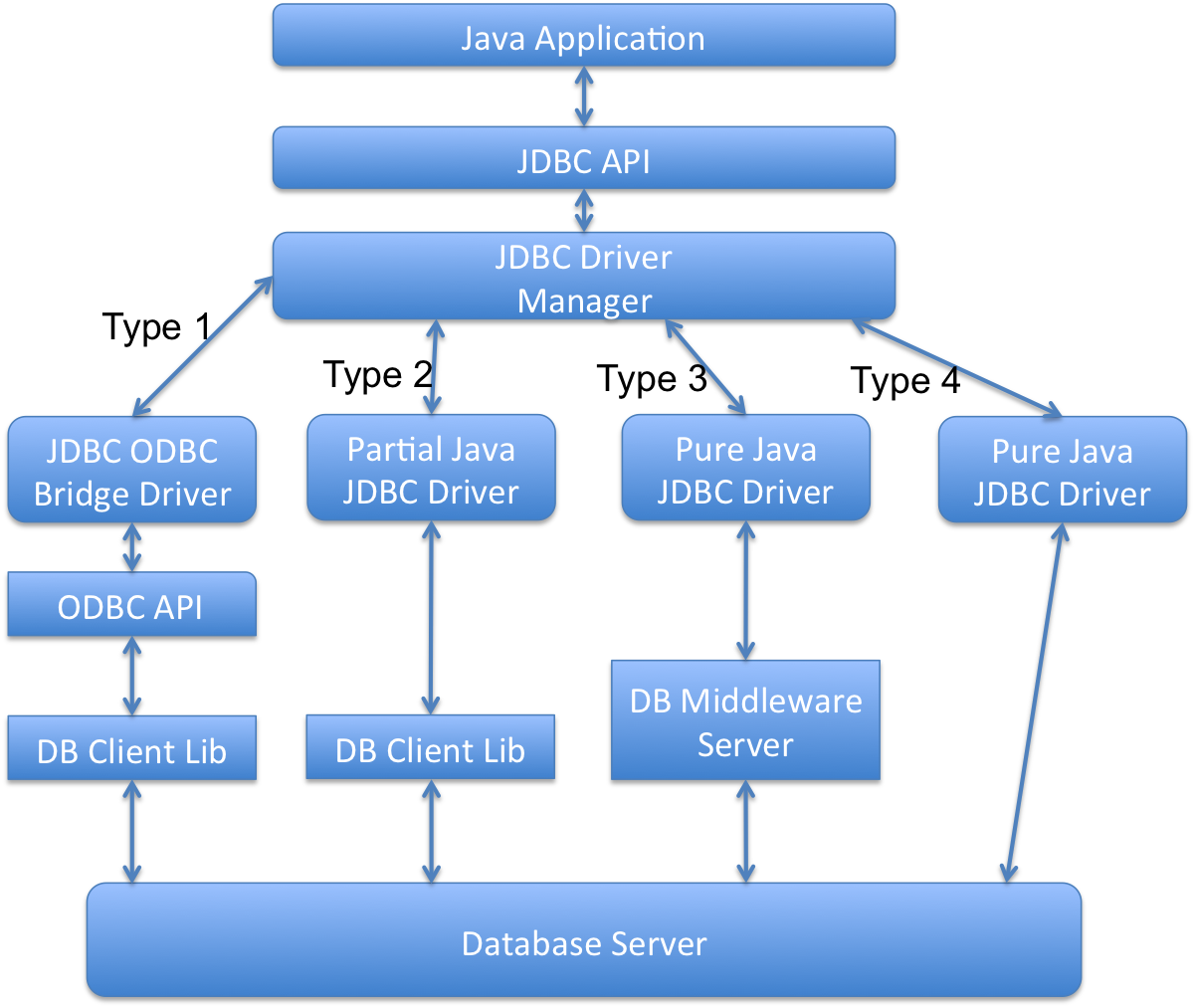
Различают четыре типа драйверов.Java программа работает с БД в двух частях. Первая часть это JDBC API, а вторая — драйвер, который и выполняет всю работу. Каждый тип определяет реализацию JDBC драйвера по возрастающей степени независимости от платформы, производительности и легкости администрирования. Эти четыре типа следующие:
Тип 1: JDBC-ODBC бридж (JDBC-ODBC Bridge plus ODBC Driver) — транслирует JDBC в ODBC и для взаимодействия с базой данных использует драйвер ODBC. Компания Sun включила в состав JDK один такой драйвер — мост JDBC/ODBC. Сейчас имеются более удачные реализации.
Тип 2: Нативный API/частично Java драйвер (Native API partly Java technology-enabled driver) — переводит вызовы JDBC в вызовы специфичные к СУБД таких как например SQL Server, Informix, Oracle или Sybase. Драйвер 2-го типа общается напрямую с сервером базы данных, следовательно он требует, чтобы какой то бинарный код был на стороне клиентской машины.
Тип 3: Сетевой протокол/«чистый» Java драйвер (Pure Java Driver for Database Middleware) — использует трехуровневую архитектуру, где вызовы JDBC посылаются на промежуточный т.н. сервер приложений, далее этот сервер транслирует вызовы (явно или косвенно) в вызовы специфичного к СУБД нативного интерфейса для дальнейшего обращения к базе данных. Если сервер среднего слоя написан на Java то он может использовать для трансляции JDBC драйверы 1 и 2 типов.
Тип 4: Нативный протокол/«чистый» Java драйвер (Direct-to-Database Pure Java Driver) — конвертирует вызовы JDBC в специфический протокол вендора СУБД, так что клиентские приложения могут напрямую обращаться с сервером базы данных. Драйверы 4-го типа полностью реализуются на Java с целью достижения платформенной независимости и устранения проблем администрирования и развертывания.
В дебрях JDBC драйверов: http://www.javable.com/javaworld/07_00/02/
10. Как JDBC API помогает достичь слабой связи между Java программой и JDBC Drivers API?
JDBC API используют рефлексию в java для достижения слабой связи между джава программой и JDBC драйверами. Драйвер фактически загружается один раз с помощью Class.forName(), а дальше используются возможности JDBC API в Java. Таким образом мы пишем код не особо задумываясь с какой базой данных мы будем работать. При необходимости достаточно указать другой драйвер и не переписывать большое количество кода.
11. Что такое JDBC Connection? Покажите шаги для подключения программы к базе данных.
JDBC Connection — соединение, установленное с сервером базы данных. Это своего рода сессия или Socket Connection. Для создания JDBC connection требуется всего два шага:
1) Зарегистрировать и загрузить драйвер с помощью Class.forName(). Класс драйвера будет зарегистрирован для DriverManager и загружен в память.
2) Используя DriverManager.getConnection() получить объект Connection. В метод необходимо передать URL базы данных, имя и пароль.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
Connection con = null; try{ // load the Driver Class Class.forName("com.mysql.jdbc.Driver"); // create the connection now con = DriverManager.getConnection("jdbc:mysql://localhost:3306/UserDB", "pankaj", "pankaj123"); }catch (SQLException e) { System.out.println("Check database is UP and configs are correct"); e.printStackTrace(); }catch (ClassNotFoundException e) { System.out.println("Please include JDBC MySQL jar in classpath"); e.printStackTrace(); } |
12. Как используется JDBC DriverManager class?
JDBC DriverManager — фабрика, через которую можно получить объект Database Connection. После загрузки JDBC драйвера в память, он регистрирует себя в DriverManager (что можно проверить посмотрев в исходники JDBC Driver class). DriverManager используется для получения подключения с помощью зарегистрированных драйверов (метод getConnection()).
13. Как получить информацию о сервере базы данных из java программы?
С помощью объекта интерфейса DatabaseMetaData можно получить детальную информацию о сервере. После подключения к БД мы можем вызывать метод getMetaData() и получить объект DatabaseMetaData. Существует множество методов для получения различной информации, например о версии БД, конфигурации и т.п..
|
1 2 |
DatabaseMetaData metaData = con.getMetaData(); String dbProduct = metaData.getDatabaseProductName(); |
14. Что такое JDBC Statement?
JDBC API Statement используется для выполнения SQL запросов к базе данных. Объект Statement можно получить с помощью метода Connection.getStatement(). Вызывая методы execute(), executeQuery(), executeUpdate() и др., можно выполнять различные статичные SQL запросы.
В случае динамически созданных SQL запросов внутри java программы, когда введенные пользователем данные могут быть не проверенными, можно использовать SQL injection.
По умолчанию только один объект ResultSet для каждого Statement может быть открыт в одно и то же время. Таким образом, если необходимо работать с несколькими объектами ResultSet одновременно, мы должны использовать различные объекты Statement. Все execute() методы в интерфейсе Statement закроют текущий открытый объект ResultSet при выполнении.
15. Какие различия между execute, executeQuery, executeUpdate?
Существует несколько способов выполнять SQL-запросы в зависимости от типа этого запроса. Для этого у интерфейса Statement существует три различных метода: executeQuery(), executeUpdate(), а так же execute(). Рассмотрим их отдельно.
Самый базовый метод executeQuery() необходим для запросов, результатом которых является один единственный набор значений, таких как у запросов SELECT. Возвращает ResultSet, который не может быть null даже если у результата запроса не было найдено значений.
Метод execute() используется, когда операторы SQL возвращают более одного набора данных, более одного счетчика обновлений или и то, и другое. Метод возвращает true, если результатом является ResultSet, как у запроса SELECT. Вернет false, если ResultSet отсутствует, например при запросах вида Insert, Update. С помощью методов getResultSet() мы можем получить ResultSet, а getUpdateCount() — количество обновленных записей.
Метод executeUpdate() используется для выполнения операторов INSERT, UPDATE или DELETE, а также для операторов DDL (Data Definition Language — язык определения данных), например, CREATE TABLE и DROP TABLE. Результатом оператора INSERT, UPDATE, или DELETE является модификация одной или более колонок в нуле или более строках таблицы. Метод executeUpdate() возвращает целое число, показывающее, сколько строк было модифицировано. Для выражений типа CREATE TABLE и DROP TABLE, которые не оперируют над строками, возвращаемое методом executeUpdate() значение всегда равно нулю.
Все методы выполнения SQL-запросов закрывают предыдущий набор результатов (result set) у данного объекта Statement. Это означает, что перед тем как выполнять следующий запрос над тем же объектом Statement, надо завершить обработку результатов предыдущего (ResultSet).
16. Что такое JDBC PreparedStatement?
Объект PreparedStatement используется для выполнения прекомпилированных SQL-запросов с или без входных (IN) параметров. Мы можем использовать сеттеры для установки значений в запрос. Т.к. PreparedStatement является предкомпилированным, то он может быть эффективно использован множество раз. PreparedStatement считается лучшим выбором нежели Statement, т.к. он автоматически обрабатывает специальные символы, а так же предотвращает, так называемые, SQL injection attack (когда в запрос можно подставить свой код).
17. Как установить NULL значения в JDBC PreparedStatement?
Используя метод setNull() для установки null переменной в качестве параметра. Этот метод принимает индекс и SQL тип в качестве аргументов: s.setNull(10, java.sql.Types.INTEGER);
18. Как используется метод getGeneratedKeys() в Statement?
Если в таблице используется автоматическая генерация ключей, то для их получения используется метод Statement getGeneratedKeys(), который вернет сгенерированный ключ.
19. Какие преимущества в использовании PreparedStatement над Statement?
- PreparedStatement позволяет предотвратить атаки типа SQL injection, т.к. он автоматически экранирует специальные символы.
- PreparedStatement позволяет использовать динамические запросы с внедрением параметров.
- PreparedStatement быстрее Statement. Это особенно заметно при частом использовании PreparedStatement или при использовании для вызова группы запросов.
- PreparedStatement позволяет писать объектно ориентированный код с использованием сеттеров\геттеров. В то время при использовании Statement необходимо использовать конкатенацию строк для создания запроса. Для больших запросов конкатенация выглядит, как минимум, большой, а так же несет в себе большой риск ошибки в запросе.
JDBC Statement vs PreparedStatement – SQL Injection Example: http://www.journaldev.com/2489/jdbc-statement-vs-preparedstatement-sql-injection-example
20. Какие есть ограничения PreparedStatement и как их преодолеть?
В PreparedStatement нельзя использовать напрямую запросы с IN (входными) параметрами. Есть некоторые обходные пути:
- Выполнить Single Queries – низкая производительность и вообще не рекомендуется так делать.
- Использовать Stored Procedure (хранимые процедуры) – являются специфичными для конкретной базы данных и следовательно плохи для приложений с возможностью подключения к различным БД.
- Создание PreparedStatement Query динамически – это хорошее решение, но с потерей кэширования PreparedStatement.
- Использование NULL в PreparedStatement Query – хорошее решение, если вы знаете максимальное число переменных IN. Можно расширить до использования неограниченного кол-во параметров с помощью разбиения на части.
JDBC PreparedStatement IN clause alternative approaches: http://www.journaldev.com/2521/jdbc-preparedstatement-in-clause-alternative-approaches
21. Что такое JDBC ResultSet?
JDBC ResultSet — интерфейс, объект которого создается в результате запроса к базе данных. Его можно представить в виде таблицы данных, которая была сформирована в ответ на запрос.
Объект ResultSet поддерживает курсор, который указывает на текущую строку данных. При инициализации курсор устанавливается до первой строки. Для движение по строкам используется метод next(). При наличии строк после текущей позиции, метод next() возвращает true, что можно использовать для итерации по таблице полученных результатов.
По умолчанию объект ResultSet не модифицируемый и поддерживает курсор, который способен только к движение вперед. Для обхода такого ограничения можно использовать следующую конструкцию, которая даст возможность двунаправленного движения по таблице, а так же возможности обновления:
|
1 2 |
Statement stmt = con.createStatement(ResultSet.TYPE_SCROLL_INSENSITIVE, ResultSet.CONCUR_UPDATABLE); |
Объект ResultSet автоматически закрывается при закрытии объекта, который его сгенерировал. Так же закрытие произойдет при повторном выполнении запроса или возврату результата из другого набора результатов.
Для использования геттера ResultSet можно использовать имя колонки или индекс, который начинается с 1.
22. Какие существуют различные типы JDBC ResultSet?
При создании Statement можно задать различные типы получаемого ResultSet.
Три типа объектов ResultSet:
- ResultSet.TYPE_FORWARD_ONLY: тип по умолчанию. Поддерживает движение курсора только в прямом направлении.
- ResultSet.TYPE_SCROLL_INSENSITIVE: Двунаправленный курсор. Объект не чувствителен к изменениям, которые произошли с таблицей после получения результата.
- ResultSet.TYPE_SCROLL_SENSITIVE: Двунаправленный курсор. Объект чувствителен к изменениям, которые произошли с базой данных после создания объекта ResultSet.
Два типа потокобезопасных объектов ResultSet:
- ResultSet.CONCUR_READ_ONLY: Поддерживает только чтение (read only). Применяется по умолчанию.
- ResultSet.CONCUR_UPDATABLE: Поддерживает метод ResultSet update для обновления строк в таблице данных.
23. Как используются методы setFetchSize() и SetMaxRows() в Statement?
Для ограничения количества строк, которые может вернуть запрос, применяется метод setMaxRows(int i). Конечно, этот результат можно получить используя SQL запрос (например для MySQL существует команда LIMIT).
Для понимания метода setFetchSize() необходимо разобраться с работой Statement и ResultSet. Когда выполняется запрос к базе данных, результат обрабатывается и сохраняется в кэше базы данных и возвращается в виде ResultSet. ResultSet является курсором, который ссылается на результат в базе данных. Теперь допустим мы имеем запрос, который возвращает 100 строк и мы установили setFetchSize(10). Теперь для каждого обращения к базе данных выделено только 10 строк и понадобится 10 запросов, чтобы получить все данные. Выбор оптимального количества fetchSize() может улучшить производительность выполнения большого кол-ва обращений к каждой строке и в случае большого количества строк в выходном результате.
Значение fetchSize можно указать внутри объекта Statement, но оно может быть переопределено в объекте ResultSet с помощью setFetchSize().
24. Как вызвать Stored Procedures используя JDBC API?
Хранимые процедуры — это группы SQL запросов, которые компилируются в базе данных и могут быть вызваны с помощью JDBC API. Для вызова хранимых процедур используется объект CallableStatement. Нам необходимо задать параметры выхода OUT до выполнения CallableStatement.
|
1 2 3 4 5 6 7 8 9 10 11 |
CallableStatement stmt = con.prepareCall("{call insertEmployee(?,?,?,?,?,?)}"); stmt.setInt(1, id); stmt.setString(2, name); stmt.setString(3, role); stmt.setString(4, city); stmt.setString(5, country); //register the OUT parameter before calling the stored procedure stmt.registerOutParameter(6, java.sql.Types.VARCHAR); stmt.executeUpdate(); |
JDBC CallableStatement Stored Procedure IN, OUT, Oracle Struct, Cursor Example Tutorial: http://www.journaldev.com/2502/jdbc-callablestatement-stored-procedure-in-out-oracle-struct-cursor-example-tutorial
25. Что такое JDBC Batch Processing и какие его преимущества?
Бывает необходимо выполнить сразу группу похожих запросов, например при загрузке данных из CSV файлов реляционной базы данных. Это можно сделать просто используя Statement или PreparedStatement для пошагового выполнения этих запросов. В JDBC API существует другая возможность, которая предоставляет возможность выполнить группу запросов за один раз. Выполнение такого рода задачи происходит с помощью JDBC API Batch Processing.
JDBC API поддерживает пакетную обработку с помощью методов addBatch() и executeBatch() у Statement и PreparedStatement. К преимуществам такого подхода относится более быстрая работа, т.к. вызовов к базе данных может быть существенно меньше.
26. Что такое JDBC Transaction Management и зачем он нужен?
По умолчанию, при создании подключения к базе данных будет выбран auto-commit mode. Это означает, что при каждом выполнении запроса он будет подтвержден автоматически по завершению. Каждый SQL запрос является транзакционным и выполняя какие-либо DML или DDL запросы по их завершению изменения будут приняты (сохранены) базой данных. Если у нас есть необходимость отказываться от сохранения выполнения какого-либо запроса (или групп запросов) в случае, если что-то пошло не так, то мы можем воспользоваться поддержкой транзакций в JDBC API.
С помощью метода setAutoCommit(boolean flag) можно отключить авто коммит в конкретном соединении. Следует отметить, что при отключении auto-commit не одно изменение не будет сохранено в базе данных до вызова метода commit() и за этим необходимо следить. Сервер базы данных будет блокировать необходимую часть базы данных до подтверждения транзакции, а так как это ресурсоёмкая задача, то подтверждать транзакцию необходимо сразу после выполнения задачи.
27. Как откатить JDBC транзакцию?
Для этого предусмотрен метод объекта Connection rollback(), который откатывает транзакцию. Будут отменены все изменения в транзакции и отменен lock базы данных от этого объекта Connection.
28. Что такое JDBC Savepoint и как он используется?
JDBC Savepoint позволяет создавать «чекпоинты» в транзакции с помощью которых мы можем откатить не всю транзакцию целиком, а только часть до точки сохранения. Любая точка сохранения автоматически освобождается и становится недоступной после подтверждения транзакции или её роллбека. Откат к точке сохранения делает все последующие сейвы недоступными и к ним уже нельзя будет вернуться.
29. Расскажите о JDBC DataSource. Какие преимущества он дает?
JDBC DataSource является интерфейсом пакета javax.sql и является более продвинутым в сравнении с DriverManager для подключения к базе данных. Мы можем использовать DataSource для создания подключения к базе данных и реализацию класса драйвера, которая будет выполнять всю работу по поддержанию соединения. В дополнение к соединению через Database, DataSource предоставляет следующие дополнительные возможности:
- Кэширование PreparedStatement для ускорения обработки запросов
- Настройки Connection timeout
- Возможности логирования
- Порог максимального размера ResultSet
- Поддержка Connection Pooling в контейнере сервлетов, использующий поддержку JNDI.
30. Как создать JDBC пул соединений используя JDBC DataSource и JNDI в Apache Tomcat Server?
Для создания пула соединений JDBC при использовании Tomcat необходимо выполнить несколько простых действий. Необходимо создать JDBC JNDI ресурс в файле конфигурации сервера (server.xml или context.xml).
server.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
<Resource name="jdbc/MyDB" global="jdbc/MyDB" auth="Container" type="javax.sql.DataSource" driverClassName="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost:3306/DataBaseName" username="root" password="admin" maxActive="100" maxIdle="20" minIdle="5" maxWait="10000"/> |
context.xml:
|
1 2 3 4 |
<ResourceLink name="jdbc/MyLocalDB" global="jdbc/MyDB" auth="Container" type="javax.sql.DataSource" /> |
В веб приложении с использованием InitialContext используем следующую запись для поиска JNDI ресурса, указанного в настройке выше. А затем можно получать соединение.
|
1 2 |
Context ctx = new InitialContext(); DataSource ds = (DataSource) ctx.lookup("java:/comp/env/jdbc/MyLocalDB"); |
к списку вопросов раздела JEE
Собеседование по Java EE — SQL, JDBC (вопросы и ответы). Часть 2.

