Databene Benerator — автоматическая генерация тестовых данных
Databene Benerator — подключение, настройка библиотеки и плагина maven-benerator-plugin. Генерация большого количества различных данных с использованием шаблонов, подзапросов, констант и т.д.
Используемые технологии и библиотеки
- Databene Benerator 0.9.8
- maven-benerator-plugin 0.7.7
- Oracle 11g XE
1. Описание задачи
Рассмотреть использование библиотеки Databene Benerator для генерации больших объемов тестовых данных. Подключить maven плагин для удобного запуска генерации. Рассмотреть различные настройки создания таблиц и данных, таких как применение паттернов regex, подзапросов, использование шаблонизаторов и многих других.
2. Структура проекта

Для генерации данных нам необходим только каталог resource\benerator. В нем находятся скрипты создания таблиц и настройки подключения к бд (benerator/oracle). Различные настройки и варианты генерации данных. Пакет db.migration используется для плагина flyway, а так же в нем находится скрипт создания схемы для БД Oracle. Большая часть настроек pom.xml описана в отдельной статье (Flyway — подключение, настройка библиотеки и плагина flyway-maven-plugin).
3. pom.xml
Как было указано чуть выше, большая часть настроек описана в статье по подключению flyway. Под катом приведу общий файл настроек maven, а затем отдельно необходимые настройки только для библиотеки benerator.
pom.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 |
<?xml version= "1.0" encoding= "UTF-8"?> <project xmlns= "http://maven.apache.org/POM/4.0.0" xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation= "http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>ru.javastudy</groupId> <artifactId>js-benerator</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <jdk.version>1.8</jdk.version> <ojdbc6.version>12.1.0.2</ojdbc6.version> </properties> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.3</version> <configuration> <source>${jdk.version}</source> <target>${jdk.version}</target> </configuration> </plugin> <plugin> <groupId>org.flywaydb</groupId> <artifactId>flyway-maven-plugin</artifactId> <version>4.0.3</version> </plugin> <plugin> <groupId>org.databene</groupId> <artifactId>maven-benerator-plugin</artifactId> <version>0.7.7</version> <configuration> <xmlRoot>setup</xmlRoot> <!--<descriptor>${project.build.outputDirectory}/benerator/jss.ben.xml</descriptor>--> <descriptor>${project.build.outputDirectory}/benerator/shop.ben.xml</descriptor> <encoding>UTF-8</encoding> <!--used for benerator:dbsnapshot. Also need ojdbc dependency--> <dbDriver>${db.driver}</dbDriver> <dbUrl>${db.url}</dbUrl> <dbUser>${db.adm.user}</dbUser> <dbPassword>${db.adm.pass}</dbPassword> <dbSchema>${db.schema}</dbSchema> </configuration> <dependencies> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>${ojdbc6.version}</version> </dependency> </dependencies> </plugin> <plugin> <artifactId>maven-resources-plugin</artifactId> <version>3.0.1</version> <executions> <execution> <id>copy-resources</id> <phase>validate</phase> <goals> <goal>copy-resources</goal> </goals> <configuration> <encoding>UTF-8</encoding> <!--classpath:db/migration is target/classes/db/migration--> <outputDirectory>${project.build.outputDirectory}</outputDirectory> <resources> <resource> <directory>src/main/resources/</directory> <filtering>true</filtering> </resource> </resources> </configuration> </execution> </executions> </plugin> </plugins> <!--Instructing the resources plugin to filter certain directories--> <resources> <resource> <directory>src/main/resources</directory> <filtering>true</filtering> </resource> </resources> </build> <profiles> <profile> <id>js-flyway</id> <activation> <activeByDefault>true</activeByDefault> </activation> <properties> <!--common properties for database connection--> <db.driver>oracle.jdbc.driver.OracleDriver</db.driver> <db.url>jdbc:oracle:thin:@localhost:1521:XE</db.url> <db.username>js</db.username> <db.password>jsadmin</db.password> <db.schema>JS</db.schema> <db.adm.user>admin</db.adm.user> <db.adm.pass>123456</db.adm.pass> <!-- Properties are prefixed with flyway. --> <flyway.user>${db.adm.user}</flyway.user> <flyway.password>${db.adm.pass}</flyway.password> <flyway.schemas>${db.schema}</flyway.schemas> <flyway.driver>${db.driver}</flyway.driver> <flyway.url>${db.url}</flyway.url> <flyway.locations>db/migration/init/</flyway.locations> </properties> </profile> </profiles> <dependencies> <!--need for flyway plugin--> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>${ojdbc6.version}</version> </dependency> <!--Generate test data--> <dependency> <groupId>org.databene</groupId> <artifactId>databene-benerator</artifactId> <version>0.9.8</version> </dependency> </dependencies> <!-- for oracle ojdbc --> <repositories> <repository> <id>codelds</id> <url>https://code.lds.org/nexus/content/groups/main-repo</url> </repository> </repositories> </project> |
Теперь отдельно необходимые для работы с плагином и библиотекой databene настройки.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
<plugin> <groupId>org.databene</groupId> <artifactId>maven-benerator-plugin</artifactId> <version>0.7.7</version> <configuration> <xmlRoot>setup</xmlRoot> <descriptor>${project.build.outputDirectory}/benerator/shop.ben.xml</descriptor> <encoding>UTF-8</encoding> <!--used for benerator:dbsnapshot. Also need ojdbc dependency--> <dbDriver>${db.driver}</dbDriver> <dbUrl>${db.url}</dbUrl> <dbUser>${db.adm.user}</dbUser> <dbPassword>${db.adm.pass}</dbPassword> <dbSchema>${db.schema}</dbSchema> </configuration> <dependencies> <dependency> <groupId>com.oracle</groupId> <artifactId>ojdbc6</artifactId> <version>${ojdbc6.version}</version> </dependency> </dependencies> </plugin> |
Тут всё достаточно очевидно из названий. Настройки указанные в ${ } описаны в отдельной статье, указанной в начале. Обратить внимание стоит на <descriptor> — это именно то, что мы будем выполнять при генерации данных. Вторая неочевидная настройка — зависимость для драйвера Oracle. По умолчанию библиотека не сообразит каким образом подключиться к базе данных Oracle и ей нужно в явном виде указать драйвер.
Еще одной добавленной зависимостью относительно проекта с flyway является сама библиотека databene-benerator.
|
1 2 3 4 5 6 |
<!--Generate test data--> <dependency> <groupId>org.databene</groupId> <artifactId>databene-benerator</artifactId> <version>0.9.8</version> </dependency> |
Если поковыряться внутри, то можно найти, например, классы шаблонизаторы. С их помощью могут создаваться данные вроде адреса электронной почты, даты, ФИО людей и т.п..
4. Обзор демонстрационного проекта
В этой статье используется встроенный demo от авторов библиотеки, который эмулирует БД для обычного магазина. Здесь рассматривается немного урезанная версия, чтобы не путать читателя кучей настроек. Если кому-то будет интересно как подключаться к другим БД или разобраться более углублено в примере, то демка находится в databene-benerator-0.9.8.jar/demo/shop/ (там же другие примеры).
5. Настройки для генерации данных
Понять как настраивать, что и как будет создаваться при использовании бенератор — самая сложная задача. Но разобравшись один раз всё станет достаточно очевидно и просто, и вы сможете использовать эти знания в различных проектах.
Сразу приведу пример главного исполняемого файла, который указан в параметре <descriptor> в pom.xml.
shop.ben.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 |
<?xml version= "1.0" encoding= "iso-8859-1"?> <setup xmlns= "http://databene.org/benerator/0.7.0" xmlns:xsi= "http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation= "http://databene.org/benerator/0.7.0 http://databene.org/benerator-0.7.0.xsd"> <comment> - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - ! Demonstration file for populating the shop database. ! ! ! ! You can choose a database and a stage like this: ! ! -Dstage=development -Ddatabase=oracle ! ! ! ! These database types are provided: ! ! oracle, db2, sql_server, mysql, postgres, hsql, ! ! hsqlmem, firebird, derby, h2 ! ! ! ! ...and these stage configurations: ! ! development, perftest ! ! ! ! Set up your database connection in the file ! ! <database>/shop.<database>.properties ! ! ! ! You may want to try different generation quantities in ! ! shop.<stage>.properties ! - - - - - - - - - - - - - - - - - - - - - - - - - - - - - --> </comment> <import domains = "person,net,product" /> <import platforms = "db"/> <comment>setting default values</comment> <setting name= "stage" default= "development" /> <!--oracle -resource package--> <setting name= "database" default= "oracle" /> <setting name= "dbCatalog" default= "" /> <setting name= "dbSchema" default= "" /> <setting name= "dbPassword" default= "" /> <setting name= "dbBatch" default= "false" /> <comment>import stage and database specific properties</comment> <include uri= "{ftl:${database}/shop.${database}.properties}" /> <!-- ftl: is the prefix used for scripting with FreeMarker Template Language --> <include uri= "{ftl:shop.${stage}.properties}" /> <comment>log the settings to the console</comment> <echo>Starting generation for</echo> <echo>{ftl: ${product_count + 6} products}</echo> <echo>{ftl: ${customer_count + 1} customers}</echo> <echo>{ftl: ${orders_per_customer} orders per customer}</echo> <echo>{ftl: ${items_per_order} items per order}</echo> <echo>{ftl:encoding:${context.defaultEncoding} default pageSize:${context.defaultPageSize}}</echo> <echo>{ftl:JDBC URL: ${dbUrl}}</echo> <!-- TODO use environment file --> <comment>define a database that will be referred by the id 'db' subsequently</comment> <database id= "db" url= "{dbUrl}" driver= "{dbDriver}" catalog= "{dbCatalog}" schema= "{dbSchema}" user= "{dbUser}" password= "{dbPassword}" batch= "{dbBatch}" /> <comment>drop the current tables/sequences if they exist and recreate them</comment> <execute uri= "{ftl:${database}/drop_tables.${database}.sql}" target= "db" onError= "ignore" /> <execute uri= "{ftl:${database}/create_tables.${database}.sql}" target= "db" /> <bean id= "idGen" spec= "new IncrementGenerator(1000)" /> <comment>Creating a valid base data set for regression testing by importing a DbUnit file</comment> <iterate source= "shop.dbunit.xml" consumer= "db" /> <comment>Importing some more predefined products from a CSV file</comment> <iterate source= "products.import.csv" type= "db_product" encoding= "utf-8" consumer= "db" /> <comment>You could import them from a fixed column width file as well, e.g. iterate name= "db_product" source= "products.import.fcw" pattern= "ean_code[13],name[30],category_id[9],price[8r0],manufacturer[30]" consumer= "db" /</comment> <comment> Creating products of random attributes and category and exporting them to the database as well as to a fixed column width file </comment> <generate type= "db_product" count= "{product_count}" consumer= "db"> <id name= "ean_code" generator= "new EANGenerator(true)" /> <reference name= "category_id" targetType= "db_category" source= "db" distribution= "random" /> <attribute name= "price" type= "big_decimal" min= "0.49" max= "99.99" granularity= "0.10" distribution= "cumulated" /> </generate> <comment>create customers</comment> <generate type= "db_users" count= "{customer_count}" consumer= "db"> <variable name= "person" generator= "PersonGenerator" dataset= "{country}" locale= "{locale}"/> <id name= "id" generator= "idGen" /> <attribute name= "name" script= "person.givenName + ' ' + person.familyName" /> <attribute name= "email" generator= "EMailAddressGenerator" /> <attribute name= "password" pattern= "[A-Za-z0-9]{8,12}" /> <attribute name= "active" pattern= "[01]{1}" /> <attribute name= "description" script= "person.salutation + ' ' + person.secondGivenName" /> <generate type= "db_customer" count= "1" consumer= "db"> <id name= "id" script= "db_users.id" /> <attribute name= "category" values= "'A','B','C'" /> <attribute name= "salutation" script= "person.salutation" /> <attribute name= "first_name" script= "person.givenName" /> <attribute name= "last_name" script= "person.familyName" /> <attribute name= "birth_date" nullable= "false" /> </generate> </generate> <comment>create orders for random customers and random products</comment> <generate type= "db_order" count= "{customer_count * orders_per_customer}" consumer= "db"> <id name= "id" generator= "idGen" /> <reference name= "customer_id" source= "db" targetType= "db_customer" cyclic= "true" /> <attribute name= "total_price" constant= "0" /> </generate> <comment>create order items</comment> <generate type= "db_order_item" count= "{customer_count * orders_per_customer * items_per_order}" consumer= "db"> <variable name= "product" source= "db" selector= "select ean_code, price from db_product" distribution= "cumulated" /> <id name= "id" generator= "idGen" /> <attribute name= "number_of_items" min= "1" max= "27" distribution= "cumulated" /> <reference name= "order_id" source= "db" selector= "select id from db_order where id > 1" cyclic= "true" /> <reference name= "product_ean_code" script= "product[0]" /> <attribute name= "total_price" script= "product[1] * db_order_item.number_of_items" /> </generate> <comment>Update order data, calculating the total sum of each order</comment> <iterate source= "db" type= "db_order" consumer= "db.updater()"> <attribute name= "total_price" source= "db" selector= "{{ftl:select sum(total_price) from db_order_item where order_id = ${db_order.id}}}" cyclic= "true"/> </iterate> </setup> |
Настройки
Тут достаточно много настроек и часть из них ссылаются еще и на дополнительные файлы. Рассмотрим всё по порядку.
|
1 2 |
<import domains = "person,net,product" /> <import platforms = "db"/> |
Это служебный импорт пакетов и указания типа платформы (есть другие типы, подробнее на оф. сайте). Например с помощью первой записи мы можем обратиться к такому классу: org.databene.domain.person.Person. Он в свою очередь содержит шаблоны для генерации имени, дня рождения, электронной почты и многой другой информации о «Личности».
Далее:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
<comment>setting default values</comment> <setting name= "stage" default= "development" /> <!--oracle -resource package--> <setting name= "database" default= "oracle" /> <setting name= "dbCatalog" default= "" /> <setting name= "dbSchema" default= "" /> <setting name= "dbPassword" default= "" /> <setting name= "dbBatch" default= "false" /> <comment>import stage and database specific properties</comment> <include uri= "{ftl:${database}/shop.${database}.properties}" /> <!-- ftl: is the prefix used for scripting with FreeMarker Template Language --> <include uri= "{ftl:shop.${stage}.properties}" /> |
Следующая группа определяет настройки. Вначале идет инициализации переменных ключ-значение, которые будут использованы в различных местах конфигурации. В нашем случае запись <include uri= «{ftl:${database}/shop.${database}.properties}» /> превратится в <include uri= «{ftl:oracle/shop.oracle.properties}» />. Эта та самая папка, которую вы могли заметить в описании проекта — resources/benerator/oracle/shop.oracle.properties.
|
1 2 3 4 5 6 7 8 |
<comment>log the settings to the console</comment> <echo>Starting generation for</echo> <echo>{ftl: ${product_count + 6} products}</echo> <echo>{ftl: ${customer_count + 1} customers}</echo> <echo>{ftl: ${orders_per_customer} orders per customer}</echo> <echo>{ftl: ${items_per_order} items per order}</echo> <echo>{ftl:encoding:${context.defaultEncoding} default pageSize:${context.defaultPageSize}}</echo> <echo>{ftl:JDBC URL: ${dbUrl}}</echo> |
Здесь задаются переменные для указания количества создаваемых записей, а так же путь к БД. Обратите внимание, что переменные не взяты с потолка, а указываются в файле с настройками shop.development.properties (development тоже параметр и указывался выше):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# benerator defaults context.defaultPageSize=1 context.defaultNull=true context.defaultEncoding=UTF-8 dbBatch=false locale=en country=US # scaling parameters product_count=50 customer_count=100 orders_per_customer=3 items_per_order=5 # specific data user_email=someone@somewhere.gov |
Настройки бд и выполняемых на старте скриптов:
|
1 2 3 4 5 6 7 8 |
<!-- TODO use environment file --> <comment>define a database that will be referred by the id 'db' subsequently</comment> <database id= "db" url= "{dbUrl}" driver= "{dbDriver}" catalog= "{dbCatalog}" schema= "{dbSchema}" user= "{dbUser}" password= "{dbPassword}" batch= "{dbBatch}" /> <comment>drop the current tables/sequences if they exist and recreate them</comment> <execute uri= "{ftl:${database}/drop_tables.${database}.sql}" target= "db" onError= "ignore" /> <execute uri= "{ftl:${database}/create_tables.${database}.sql}" target= "db" /> |
Переменные указывались выше в настройках. Обратить внимание стоит на теги execute. В них выполнится сначала скрипт дропа таблиц, а потом их создания. Как и ранее, при выполнении переменные ${ } превратятся в обычный текст, например oracle/drop_tables.oracle.sql.
Начало генерации данных
|
1 2 3 4 |
<bean id= "idGen" spec= "new IncrementGenerator(1000)" /> <comment>Creating a valid base data set for regression testing by importing a DbUnit file</comment> <iterate source= "shop.dbunit.xml" consumer= "db" /> |
Сначала указывается бин для инкремента, а далее подключается сторонний xml файл. Кто знаком с синтаксисом создания таблиц и данных от библиотеки DbUnit, тот сразу поймет что там внутри. Данные генерируются на основе простеньких xml записей, например:
|
1 |
<db_users id= "1" name= "alice" password= "alice" email= "alice@somewhere.com" active= "1" description= "alice"/> |
Очевидно, что здесь будет создана таблица DB_USERS с колонками ID, NAME и т.д. Далее в них будет выполнен insert указанных полей.
|
1 2 |
<comment>Importing some more predefined products from a CSV file</comment> <iterate source= "products.import.csv" type= "db_product" encoding= "utf-8" consumer= "db" /> |
Аналогичная демонстрация использования формата csv.
products.import.csv:
|
1 2 3 4 5 |
ean_code,name,category_id,price,manufacturer 8000353006386,Limoncello Liqueur,DRNK/ALCO,9.85,Luxardo 3068320018430,Evian 1.0 l,DRNK/SOFT,1.95,Danone 8076800000085,le Lasagnette,FOOD/MISC,0.89,Barilla 7610400071680,Connaisseurs,FOOD/CONF,16.95,Lindt |
Вот мы и подошли к магии от benerator.
|
1 2 3 4 5 6 7 8 9 |
<comment> Creating products of random attributes and category and exporting them to the database as well as to a fixed column width file </comment> <generate type= "db_product" count= "{product_count}" consumer= "db"> <id name= "ean_code" generator= "new EANGenerator(true)" /> <reference name= "category_id" targetType= "db_category" source= "db" distribution= "random" /> <attribute name= "price" type= "big_decimal" min= "0.49" max= "99.99" granularity= "0.10" distribution= "cumulated" /> </generate> |
Здесь создается таблица DB_PRODUCT. В id с помощью встроенного класса EANGenerator будут создаваться записи в определенном формате. Следующей строчкой идет тег <reference>. С помощью него мы ссылаемся на другую таблицу (DB_CATEGORY) и тянем оттуда в случайном порядке записи. Магия сопоставления происходит с помощью foreign key, который создается при выполнении скрипта create_tables.sql. Атрибут price особого описания не требует.
XML Теги benerator
Далее код генерации тестовых данных в целом повторяется. Рассмотрим отдельно интересные теги.
|
1 |
<variable name= "person" generator= "PersonGenerator" dataset= "{country}" locale= "{locale}"/> |
person — тот самый пакет, который был указан при импорте; generator — класс, dataset=, locale= — поля класса. Чтобы было понятнее приведу часть класса:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
package org.databene.domain.person; ....imports public class Person { private String givenName; private String secondGivenName; private String familyName; private Gender gender; private String salutation; private String academicTitle; private String nobilityTitle; private Date birthDate; private String email; private Locale locale; public Person(Locale locale) { this.locale = locale; } |
|
1 |
<attribute name= "name" script= "person.givenName + ' ' + person.familyName" /> |
Генерит с помощью класса выше имя и фамилию + происходит конкатенация строк.
|
1 |
<attribute name= "email" generator= "EMailAddressGenerator" /> |
Шаблон (класс) для электронной почты.
|
1 |
<attribute name= "password" pattern= "[A-Za-z0-9]{8,12}" /> |
Обычный шаблон с использованием регулярных выражений.
|
1 |
<attribute name= "active" pattern= "[01]{1}" /> |
Либо 0, либо 1.
|
1 2 3 |
<generate type= "db_customer" count= "1" consumer= "db"> <id name= "id" script= "db_users.id" /> .... |
Вот тут создается другая таблица DB_CUSTOMER, но на основании id из родительской таблицы.
|
1 |
<generate type= "db_order" count= "{customer_count * orders_per_customer}" consumer= "db"> |
Создается таблица DB_ORDER с количеством записей на основе переменных, указанных в начале настроек.
|
1 |
<variable name= "product" source= "db" selector= "select ean_code, price from db_product" distribution= "cumulated" /> |
Пример подзапроса к базе данных DB_PRODUCT с выборкой по двум полям и определенным типом их записи (comulated).
Еще один пример с использованием выборки и обновлению данных (суммирование) для каждого заказа:
|
1 2 3 4 5 6 |
<comment>Update order data, calculating the total sum of each order</comment> <iterate source= "db" type= "db_order" consumer= "db.updater()"> <attribute name= "total_price" source= "db" selector= "{{ftl:select sum(total_price) from db_order_item where order_id = ${db_order.id}}}" cyclic= "true"/> </iterate> |
6. Запуск генерации тестовых данных
Чтобы запустить плагин для генерации данных нужно просто выполнить команду benerator:generate.
В консоль будут выведены результаты работы плагина.

Чтобы увидеть более подробную информацию нужно добавить к команде -X. Для этого нужно нажать правой кнопкой на команду и выбрать create ‘ …’. Далее прописать в поле benerator:generate -X.
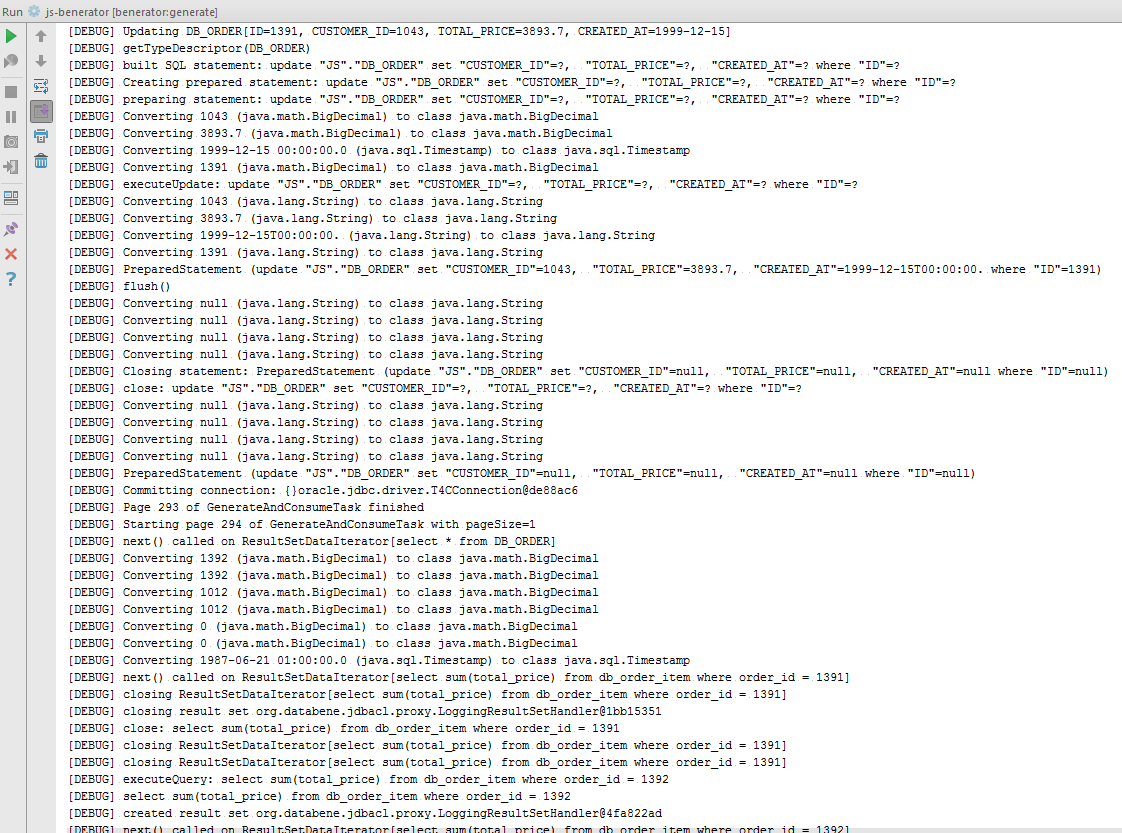
Получим подробный вывод в консоль:
Проверим что получилось по окончанию генерации.
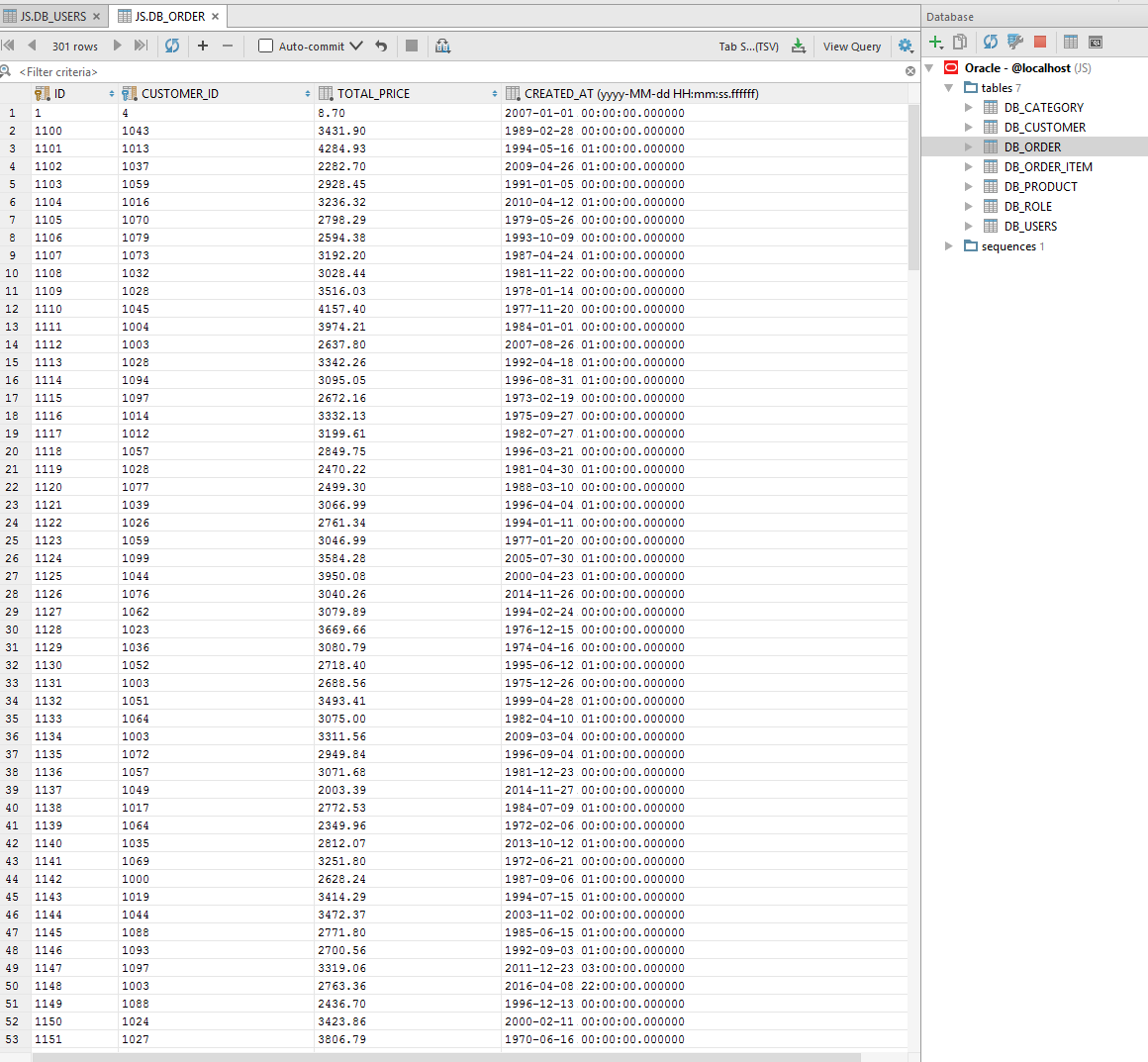
Другая таблица:
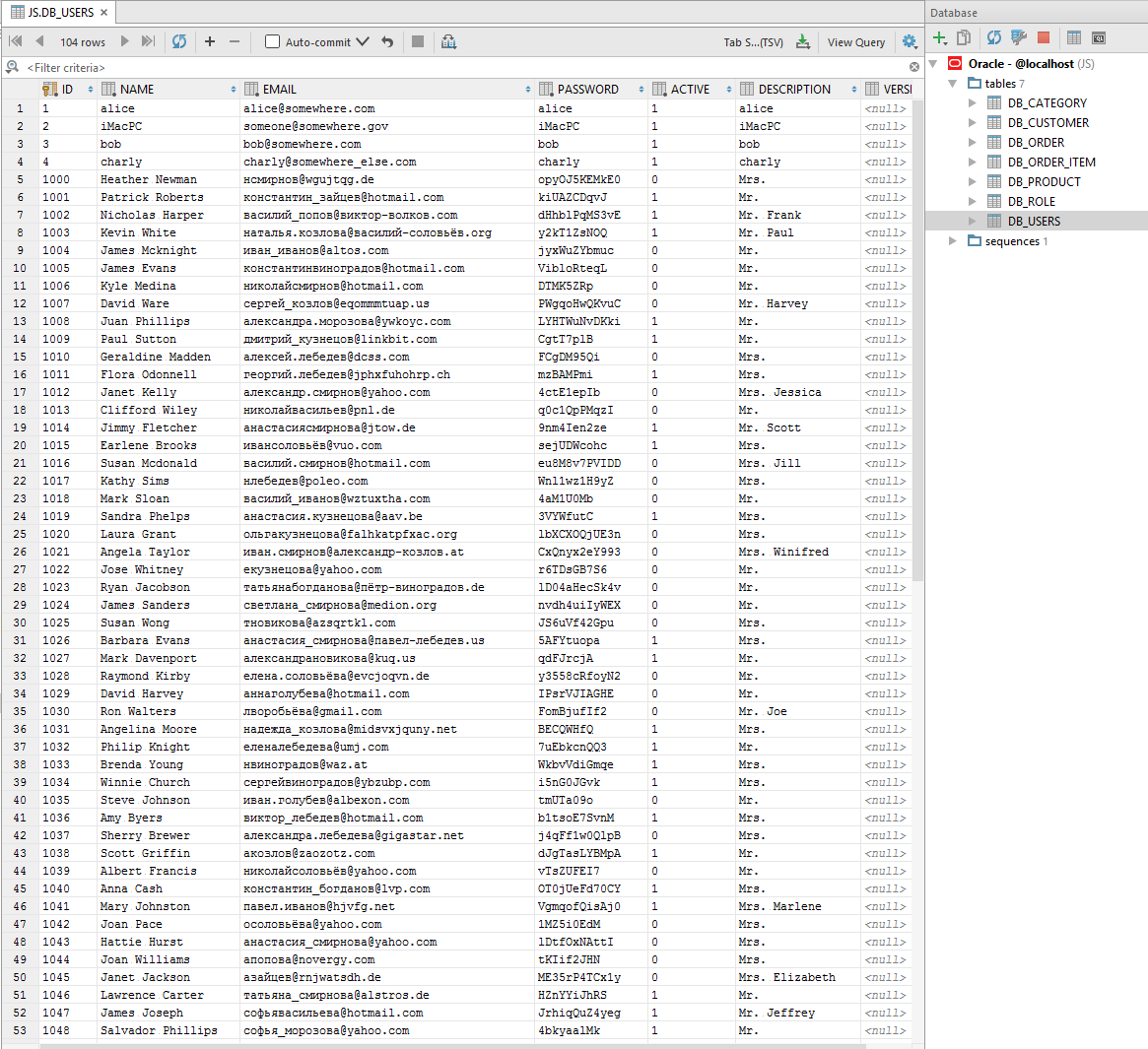
В данном примере было создано семь таблиц и записано несколько тысяч полей примерно за 10 секунд. Таким образом мы научились генерировать большие объемы тестовых данных и запись их в базу данных Oracle. Меняя различные настройки можно добиться совершенно разных данных практически под любую задачу.
Исходные коды

One thought on “Databene Benerator — автоматическая генерация тестовых данных”
Добавить комментарий
Для отправки комментария вам необходимо авторизоваться.

Урааа!!! Ты вернулся. Даешь материал по многопоточности=)